보통 실무에서 데이터를 불러올 경우 DB에서 정렬을 통하여 불러오기 떄문에 그 순서를 유지하기위해 ArrayList에 담는 경우가 많다.
처음 개발을 시작할 때는 자료구조의 'ㅈ'자도 몰라서 그냥 아무생각 없이 ArrayList의 contains 메소드를 호출하여 해당 데이터가 들어있는지 확인하였다.
허나 개발을 점점 해보면서 ArrayList의 contains는 시간복잡도가 O(n)이고 HashSet의 경우 시간복잡도가 O(1)이라 성능이 더 좋다는 것을 알게되었다.
이에 대해 ArrayList의 경우 모든 객체의 값을 하나하나 확인을 해봐야하나 HashSet의 경우 Key로 가지고 있기 때문에 바로 불러올 수 있어서 라고만 단순히 생각하였다.
그렇게 사용하던 중 정확히 내부에서 어떻게 동작하는지가 궁금해져 이번에 확인을 해보게 되었다.
ArrayList의 contains 동작 방식
우선 ArrayList의 contains 메소드의 동작방식에 대해 알아보자.

내부에서 indexOf 메소드를 호출하고 있으며 내용은 아래와 같다.
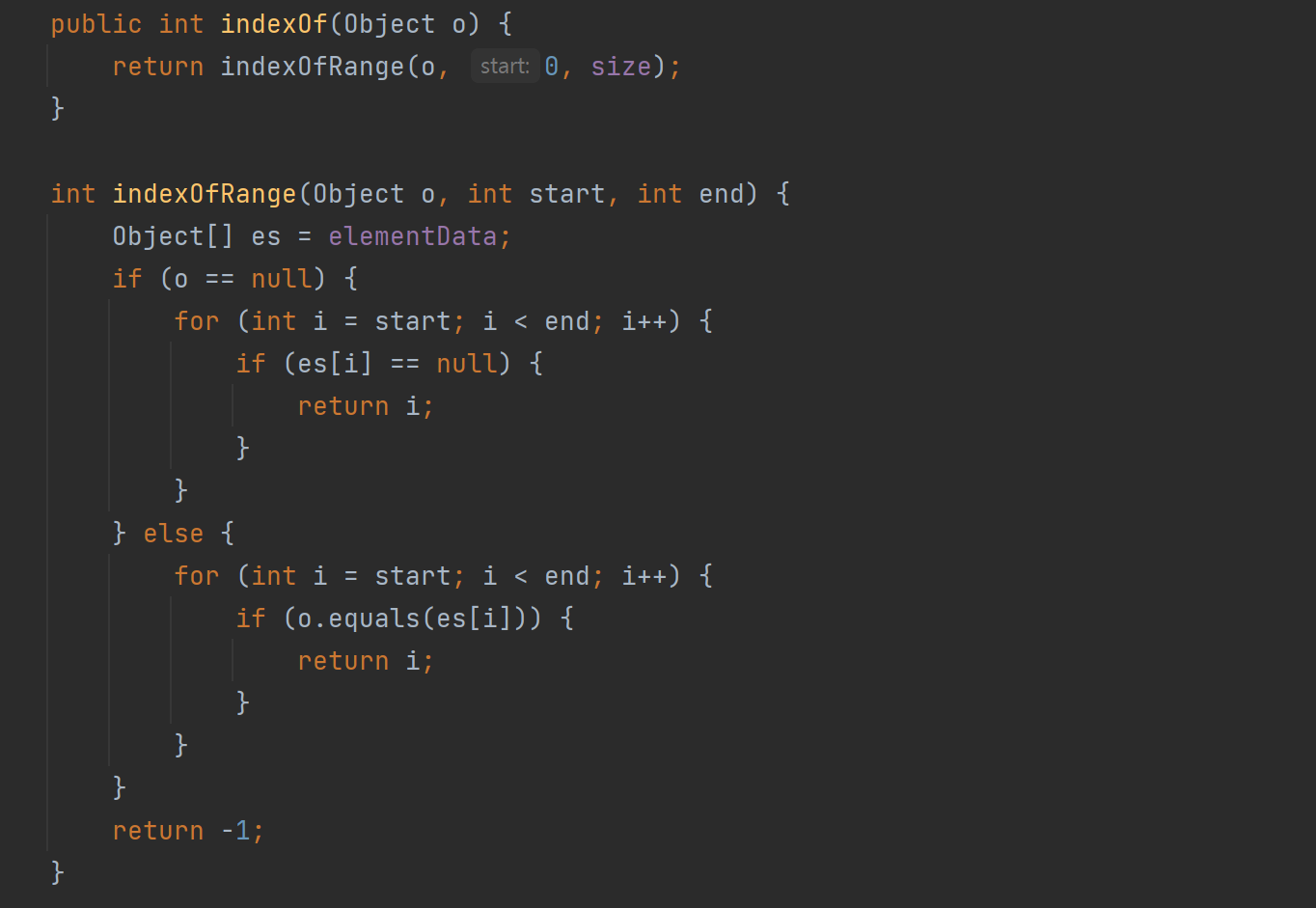
내용을 파악해보자면 ArrayList의 데이터를 가지고 있는 배열인 elementData에서 인덱스를 0부터 시작하여 해당 객체의 값(null 포함)이 몇번째 인덱스에 존재하는지 확인한다.
순차적으로 모든 인덱스를 확인하기 때문에 뒤쪽 인덱스에 저장되어 있는 데이터일수록 성능이 나빠진다.
HashSet의 contains 동작 방식
그럼 이번엔 HashSet의 contains의 동작 방식을 확인해보자.

위에서 확인했듯이 내부적으로 HashMap으로 구현하기 때문에 HashMap의 containsKey 메소드를 호출한다.
HashMap의 containsKey 메소드는 아래와 같다.

getNode 메소드를 진행하는데 getNode 메소드의 메소드는 HashMap에서 get 메소드를 진행할 때 사용하는 메소드와 동일하다.

getNode시에는 정확히 그 키 값으로 저장되어있는 객체에 접근하기 때문에 어떤 객체에 접근하던 시간복잡도는 O(1)이다.
여기서 getNode의 시간복잡도는 어떻게 O(1)을 유지할까? 라는 의문이 들어 추가로 확인해보았고
아래 글에 Java HashMap의 내부 동작 방식을 정리해두었으니 궁금하면 참고해보자.
https://potwings.tistory.com/59
Java HashMap의 내부 동작 - 이론편
해당 글은 Java8 기준으로 작성되었습니다. https://potwings.tistory.com/56 Java HashSet, HashMap 내부 구조 & List보다 contains의 성능이 더 좋은 이유 알고리즘 문제를 풀거나 실무에서 Hash 자료 구조를 자주 접
potwings.tistory.com
결론
contains를 사용해야할 일이 있을 경우 HashMap을 사용하도록 하자.
번외 - HashSet이 HashMap보다 성능이 좋지 않을까?
우선 필자는 HashSet이 HashMap보다 성능이 좋을 것이라고 생각하였다.
Set은 Key만 가지고 있고 Map은 Key와 value를 가지고 있으니 데이터를 하나만 가지고 있는 Set이 당연히 성능이 좋을 것이라 생각하였다.
하지만 HashSet의 내부를 확인해보면 아래와 같았다.
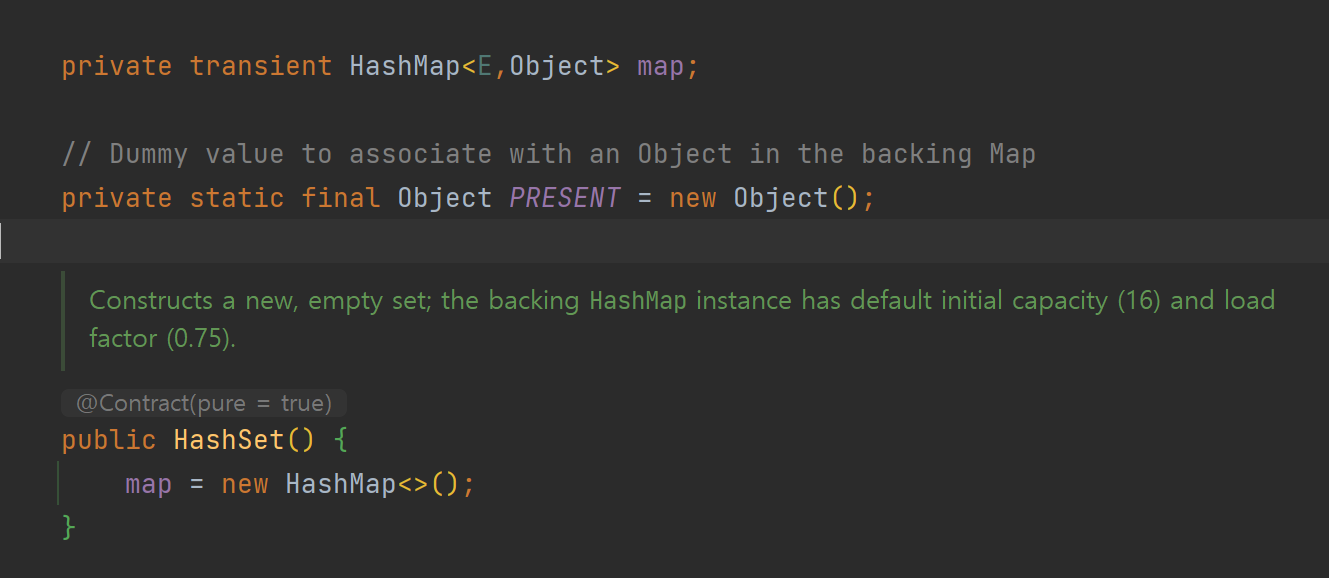
HashSet을 생성할 경우 생성자에서 HashMap을 생성해주고 있었다.
추가로 Set에 값을 추가할 경우는 PRESENT라는 객체를 value로 Map에 put하고 있었다.

PRESENT라는 변수는 아래와 같이 클래스 변수로 선언되어있었다.

주석에 써있듯이 그냥 단순히 Set의 key값을 Map에 넣어주기 위해 쓰이는 더미 객체였다.
따라서 HashSet과 HashMap의 성능 차이는 없었다.
'BackEnd > Java' 카테고리의 다른 글
| Java HashMap의 내부 동작 - 이론편 (0) | 2024.04.14 |
|---|---|
| DTO 그렇게 쓰는 거 아닌데 ㅋㅋ (0) | 2024.03.17 |
| JAVA 객체 배열, 리스트 값 비교(Comparable, Comparator)를 통한 정렬 (0) | 2023.09.03 |
| JAVA에 Call by refernce는 없다. (0) | 2023.07.03 |
| JAVA equals, hashCode 메소드 (0) | 2023.05.18 |